Existen dos funciones en seaborn para crear gráficos de dispersión con rectas de regresión: regplot y lmplot. A pesar de que las funciones son muy similares, tienen pequeñas diferencias. La salida de lmplot es una figura cuadrada, requiere el argumento data y permite visualizar la relación entre variables en base a una variable categórica mientras que regplot no, además de otras diferencias.
Datos de muestra
Los siguientes datos serán usandos en los ejemplos de este tutorial. Ten en cuenta que la función lmplot requiere un data frame de pandas como argumento mientras que regplot se puede utilizar sin establecer el argumento data.
import numpy as np
import pandas as pd
from random import choices
# Semilla
rng = np.random.RandomState(0)
# Simulación de datos
x = rng.uniform(0, 1, 300)
y = 5 * x + rng.normal(0, 2, size = 300)
grupo = choices(["A", "B"], k = 300)
x = x + rng.uniform(-0.2, 0.2, 300)
# Conjunto de datos
df = {'x': x, 'y': y, 'grupo': grupo}
# Data frame pandas
df = pd.DataFrame(data = df)
Recta de regresión con regplot
Para crear un gráfico de dispersión en seaborn con una recta de regresión pasa tus datos a la función regplot. Ten en cuenta que tanto las observaciones como las estimaciones tendrán por defecto el mismo color.
import seaborn as sns
sns.regplot(x = x, y = y)
# Equivalente a:
sns.regplot(x = "x", y = "y", data = df)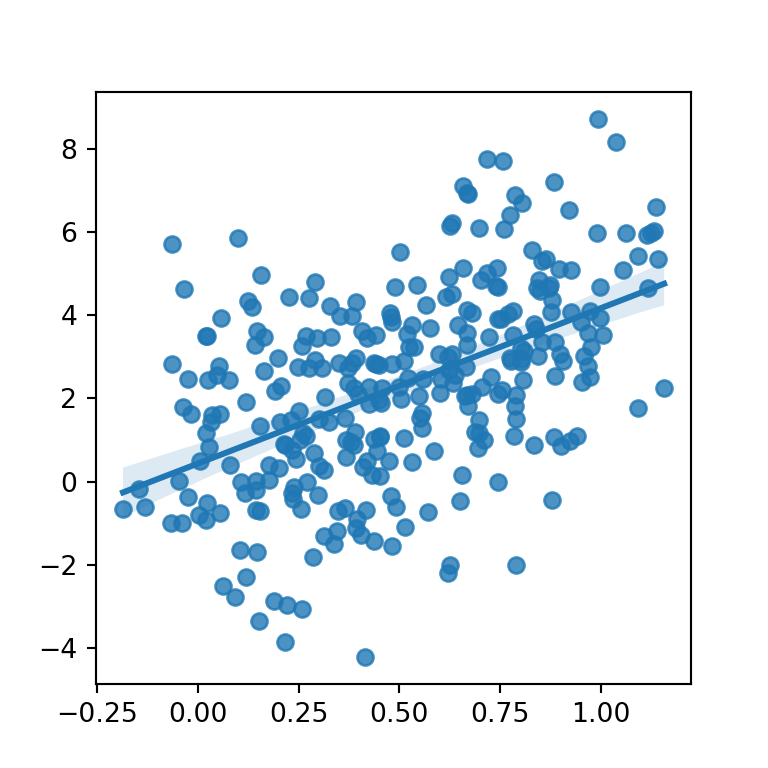
Colores diferentes para puntos y estimaciones
Si necesitas modificar los colores por defecto de los puntos y de la recta de regresión y su intervalo de confianza tendrás que pasar diccionarios a los argumentos scatter_kws y line_kws, respectivamente, tal y como se muestra en el siguiente ejemplo.
import seaborn as sns
sns.regplot(x = x, y = y,
scatter_kws = {"color": "black", "alpha": 0.5},
line_kws = {"color": "red"})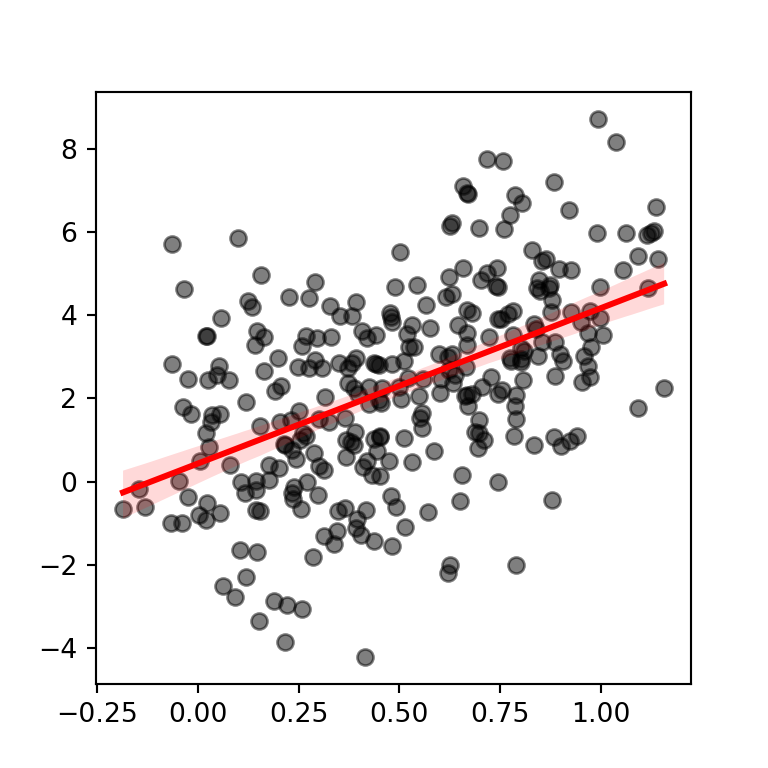
Nivel del intervalo de confianza
Por defecto, el intervalo de confianza se dibuja al 95%. Sin embargo, puedes usar el argumento ci para modificar el nivel o eliminar la estimación estableciendo el argumento como None.
import seaborn as sns
sns.regplot(x = x, y = y,
scatter_kws = {"color": "black", "alpha": 0.5},
line_kws = {"color": "red"},
ci = 99) # Intervalo al 99%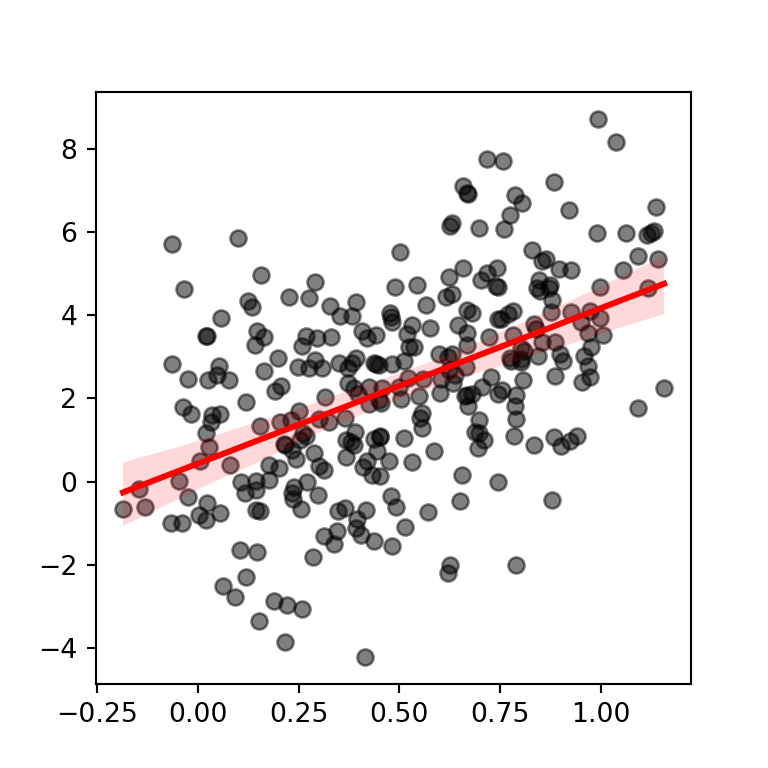
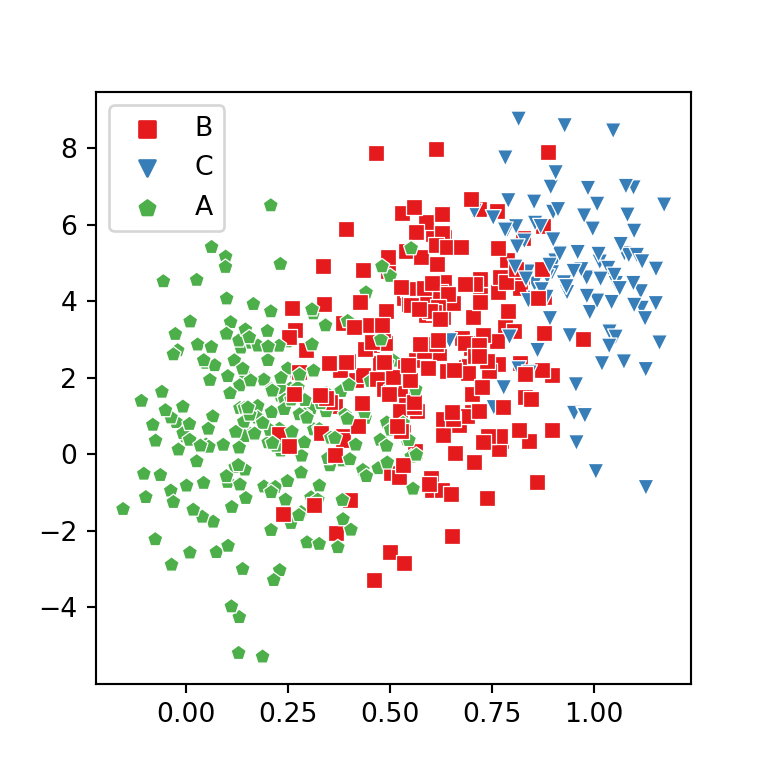
Rectas de regresión por grupos con lmplot
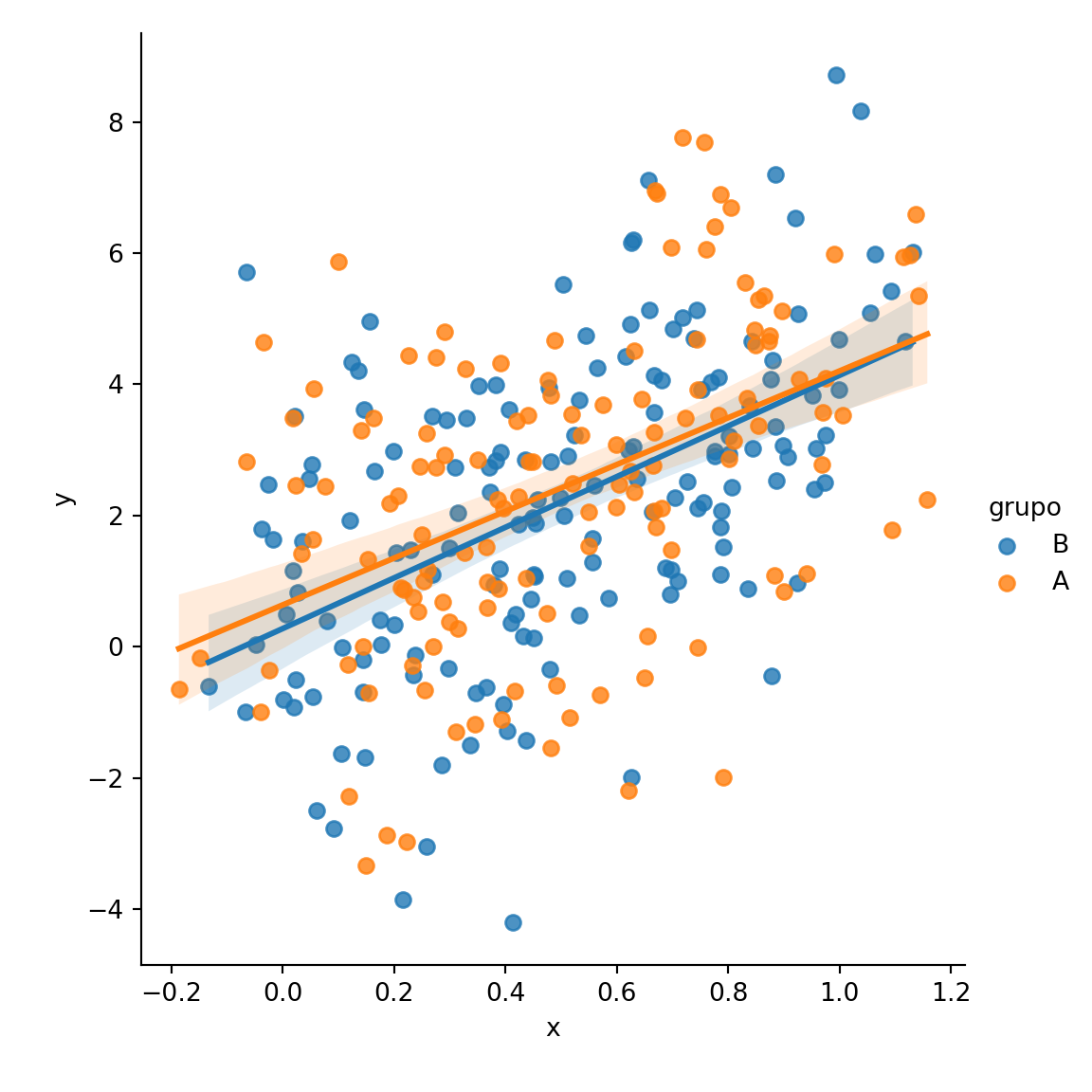
La función lmplot permite crear rectas de regresión basadas en una variable categórica. Tan solo tienes que pasar la variable al argumento hue de la función. Ten en cuenta que esta función requiere especificar el argumento data con un data frame como input.
import seaborn as sns
sns.lmplot(x = "x", y = "y",
hue = "grupo", data = df)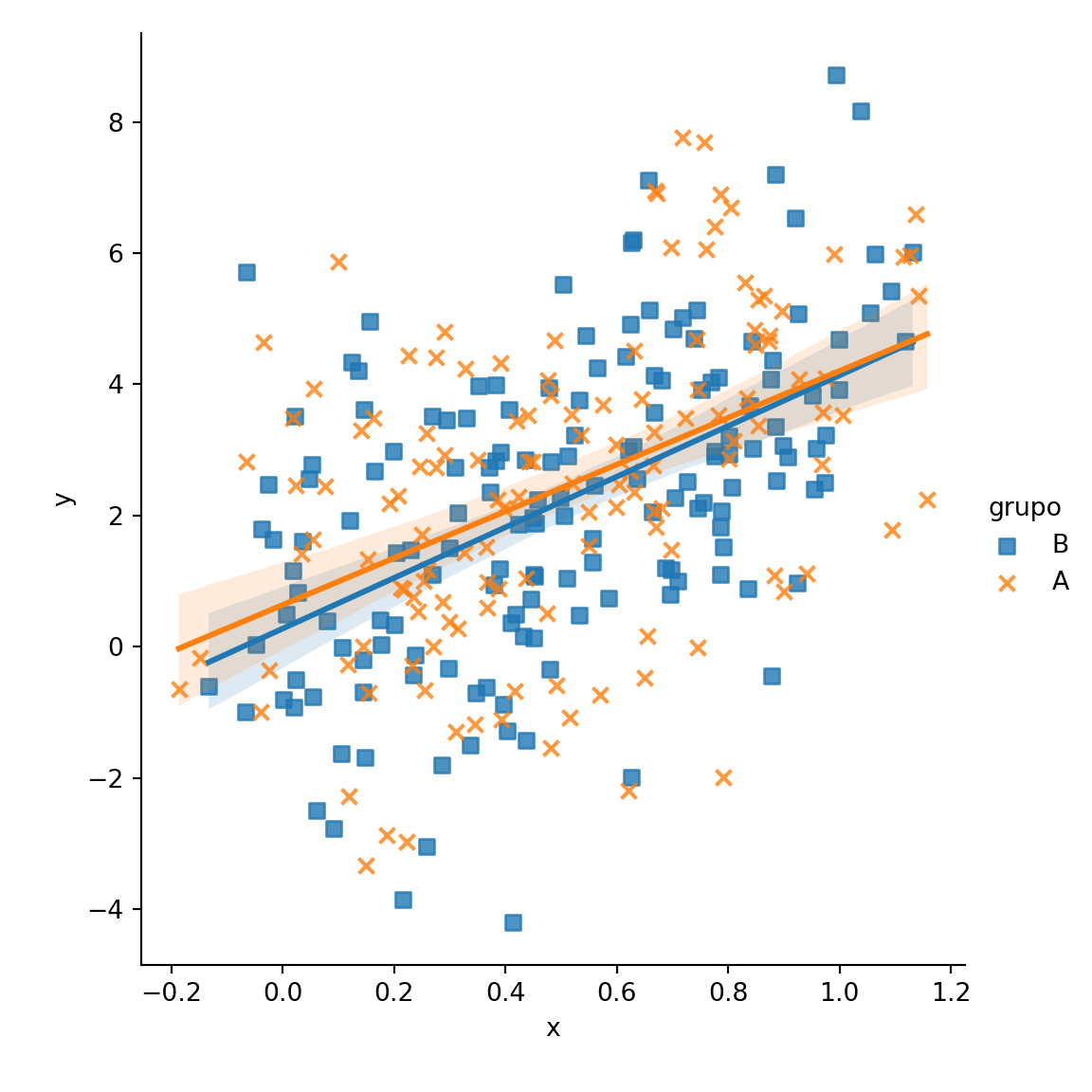
Símbolos diferentes para cada grupo
El argumento markers permite personalizar la forma de los símbolos del gráfico, tal y como se muestra a continuación.
import seaborn as sns
import matplotlib.pyplot as plt
sns.lmplot(x = "x", y = "y",
hue = "grupo", markers = ["s", "x"],
data = df)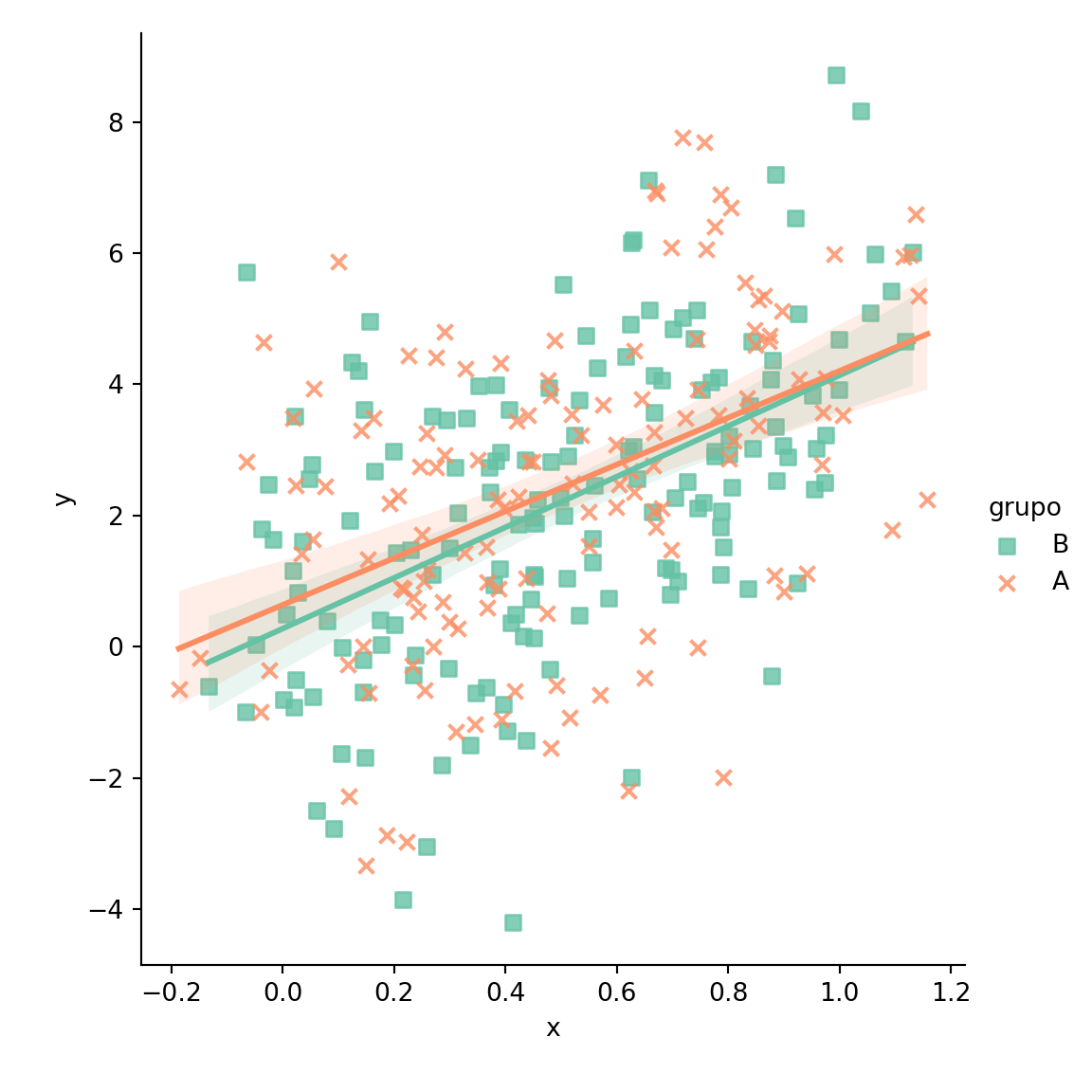
Paleta de colores
Ten en cuenta que puedes sobrescribir la paleta de colores por defecto con el argumento palette de la función.
import seaborn as sns
import matplotlib.pyplot as plt
g = sns.lmplot(x = "x", y = "y",
hue = "grupo", markers = ["s", "x"],
palette = "Set2",
data = df)
g.fig.set_size_inches(6, 6)
plt.show()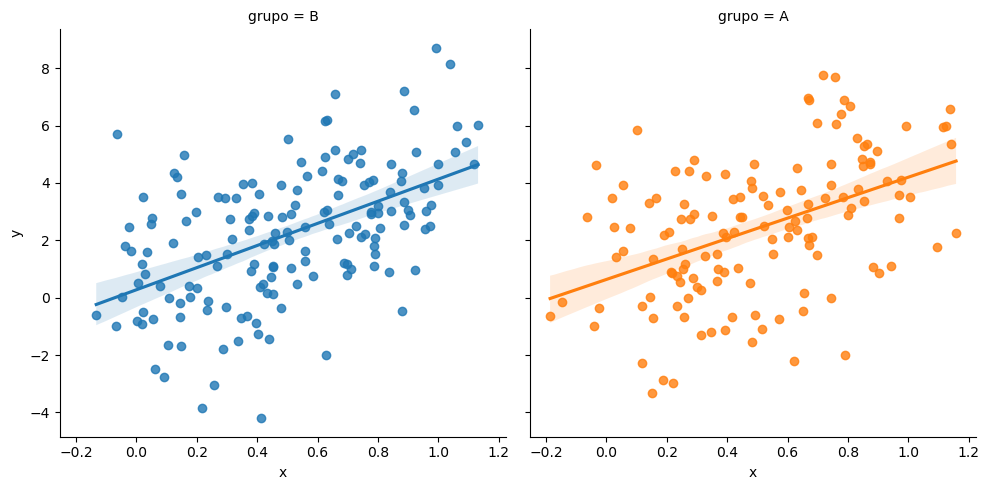
Gráfico en diferentes columnas
En los gráficos anteriores las estimaciones para ambos grupos se mostraban sobre el mismo gráfico. Si prefieres dibujar las estimaciones en varias columnas del mismo gráfico puedes pasar la variable categórica al argumento col de la función.
import seaborn as sns
sns.lmplot(x = "x", y = "y",
col = "grupo", hue = "grupo",
data = df)